자바가 제공하는 다양한 연산자를 학습한다.
- 산술 연산자
- 비트 연산자
- 관계 연산자
- 논리 연산자
- instanceof
- assignment(=) operator
- 화살표(->) 연산자
- 3항 연산자
- 연산자 우선 순위
- (optional) Java 13. switch 연산자
1.산술 연산자
+ , - , * , / , % 와 같은 우리가 흔히 사용하는 연산자이다.
피연산자와 피연산자를 연산하는 이항 연산을 수행한다.
일반 수학에서 사용하는 것과 같이 사용할 수 있다.
ex) 1+1 , 2 * 3 , 4 / 2 , 4 % 3
그렇다면 우리가 일반적으로 사용하는 계산이 자바 컴파일러를 거치면 클래스 파일에서 어떻게 변환되어 계산되는지를 살펴보자. 당연하다고 생각되는 점들은 굳이 따로 집어 표현하지 않았고, 새롭게 알게 된 부분들만 집중적으로 표현하였다.


1) 변수와 변수 사이에 발생하는 연산이 아닌 연산은 컴파일 시에 하나의 값으로 연산이 미리 되어 한개의 리터럴(?)로 표현된다. (0)
2) 우리가 중위연산으로 표현한 계산들은 모두 컴파일시 우선순위에 따라 후위연산으로 변환되어 표현된다.(13 ~ 22)
-> why? 선장님과 함께하는 1차 스터디 jvm specification 에서 공부했다시피 jvm은 stack기반의 가상 실행머신이기 때문이다. 따라서 연산은 모두 Operand Stack에서 이루어진다.
3) 하나의 연산자가 클래스파일로 변환되면 연산할 자료형에 따라 여러 형태로 표현된다. 즉, 피연산자의 자료형에 따른 8개의 접두사를 가진 파생연산 opcode가 발생한다.(단 boolean은 제외되고 reference형의 접두사가 새로 생성된다.) (15, 46)
4) 서로 다른 자료형의 연산이 이루어 질 때, 가장 먼저 발생하는것은 형변환이다. 피연산자의 형변환이 먼저 이루어지고 그 후에 해당 자료형에 맞는 연산이 진행된다.(56)
** 연산자와는 전혀 관련 없는 부분이지만 jvm에서 local variable에 값이 저장될 때 4byte를 기반으로 해당 위치를 저장하는것을 깨달았다. 저번 스터디 시간에 깨우쳤어야 하는 것이었는데 미처 짚고 넘어가지 못 한 점이 아쉽다. (22 ~ 30)의 store 과정을 보면 이해할 수 있다.)
** ++와 --가 산술연산자에 포함되는지 모르겠다. 일단 이곳에 분류하자면 ++과 --가 전위 연산일 때는 그 어떤 연산보다 먼저 이루어진다. 바이트코드를 확인해보면 다음과 같다.


특이한 점이 있는데 --연산은 마이너스 연산이 일어나지 않고 해당 local variable에 -1의 값이 더해진다.
2. 비트연산자
>> , << , >>> , ~ , & , | , ^
:비트 끼리의 연산을 진행하는 연산자로 피연산자가 보통 정수인 경우에만 사용 가능하다.
|연산자와 &연산자는 피연산자가 모두 boolean 타입인 경우에도 사용할 수 있다.
<<
좌측에 있는 피연산자의 비트를 우측에 있는 피연산자의 숫자만큼 비트를 옮기는 연산자이다. 자릿수를 넘어가면 해당 비트는 사라지게 되고 비트를 옮겨 새로 생긴 자리의 비트는 0으로 대체한다.
ex)
int형의 경우
00000000 00000000 00000000 00011101 << 00000000 00000000 00000000 00000011(3)
(000)00000000 00000000 00000000 11101000
byte의 경우
10010010 << 00000010(2)
(10)01001000
>>
좌측에 있는 피연산자의 비트를 우측에 있는 피연산자의 숫자만큼 비트를 옮기는 연산자이다. 자릿수를 넘어가면 해당 비트는 사라지게 되고 비트를 옮겨 새로 생긴 자리의 비트는 이전의 최상위 비트로 대체한다.
int형의 경우
00000000 00000000 00000000 00011101 >> 00000000 00000000 00000000 00000011(3)
00000000 00000000 00000000 00000011(101)
byte의 경우
10010010 >> 00000010(2)
11100100(10)
>>>
위에서 사용한 '>>' 비트 연산과 같은데 새로생긴 자리의 비트가 무조건 0으로 따라가는것이 다르다
ex)
10000000 >>> 00000010(2)
00100000(00)
&(and)
피연산자간의 비트를 비교했을 때 두개 모두 1이면 1로 치환되고 아니면 0으로 치환된다.
ex)
10111010
01001011
-----------
00001010
|(or)
피연산자간의 비트를 비교했을 때 둘중 하나가 1이면 1로 치환된다.
ex)
10110010
01001011
-----------
11111011
^(xor)
피연산자간의 비트를 비교했을 때 두개의 비트가 다르면 1 같으면 0을 반환한다.
ex)
10110010
01001011
-----------
11111000
~
단항 연산자로 각 자리에 해당하는 비트를 모두 반전시킨다. 정확하게 말하자면 -1과 xor 연산을 한다.


ex)
10101101
11111111
-----------
01010010
**비트 연산자도 산술연산자와 마찬가지로 연산 이전에 피연산자의 자료형을 먼저 파악하고 형변환을 실행했으며, 자료형에 따른 연산자opcode가 생성되었다.
3. 관계연산자
:비교연산자라고도 말한다. 우리가 흔히 수학시간에 사용했던 (부)등호(< , > , <= , >= , =)에 !=이 추가된 형식이다. 단, =이 ==이고 =이 아니다 라는것을 표현하는것이 !=이다.

간단하다. 우리가 흔히 사용하는 형식의 비교 연산의 참거짓을 판별해준다.
그런데 컴파일하여 바이트코드를 분석해보면 조금 이상하게 변환된다.

(4~14)의 과정을 한번 살펴보자
4 < 3 의 내용이 참인지 거짓인지를 판별해야하는데 바이트코드는
if_icmpge (int형(i)의 두 피연산자를 가져와서 비교(cmp)할것인데 앞의 연산자가 크거나 같으면((g)reater than or (e)qual) 우측 해당 instruction으로 이동한다.)이다.
4와 3을 꺼내와서 4가 3보다 작을때 행동을 취하는것이 아니라 4가 3보다 크거나 같으면 우측해당 위치로 넘어가는 형식을 취한다.
????????????????????????????????????
아무리봐도 이상하다.
왜 이런 형식을 취하는 것일까? 를 생각해본 결과, 부호를 반대로 바꾸지 않으면 컴퓨터 구조상 해당내용이 참이 아닐 시 instruction이 적혀있는 곳으로 이동해야하는 방식이 되어야한다. 그런것보다는 사람이 인식하기 더 쉬운 방향으로 부호를 바꿔버리고 해당 값이 참이면 거짓으로 판별하는것이 좋을것 같다. 아마 이러한 이유때문에 변환된다는 합리적인 추론을 했지만 정확한 결과는 아직 찾아내지 못했다. 추후 확실한 내용이 파악되면 다시 정리해서 올려놓을 예정이다.
4. 논리연산자
:논리연산을 수행하고 피연산자는 boolean타입이다.
&&, & , || , | , !


바이트 코드에 해석된 대로 표현을 하자면 다음과 같은 연산을 진행한다.
&&
앞의 내용이 거짓이면 뒤는 확인하지 않고 거짓이다. 앞의 내용이 참이고 뒤의 내용이 거짓이면 거짓이다. 앞의 내용과 뒤의 내용 모두 참이면 참이다.
||
앞의 내용이 참이면 뒤는 확인하지 않고 참이다. 앞의 내용이 거짓이고 뒤의 내용이 참이면 참이다. 앞의 내용과 뒤의 내용 모두 거짓이면 거짓이다.
!
해당 피연산자가 참이면 거짓이다. 해당 피연산자가 거짓이면 참이다.
| , &
이 두 연산은 단순히 앞의 피연산자와 뒤의 피연산자의 비트연산에 불과하다. 그러나 앞의 내용에서 걸러지더라도 반드시 뒤의 내용을 확인을 같이 하고싶다면 해당 연산을 활용하여 논리 연산처럼 사용해도 무관하다.
** 논리 연산도 앞서말한바와 같이 해당 연산의 예외를 먼저 찾아내고 예외에 해당하면 거짓을 먼저 판별하는 로직을 가지고 있었다.
5. instanceof
instanceof는 참조 변수가 지정된 유형의 객체 참조를 포함하고 있는지 여부를 확인하는 데 사용되는 키워드이다.
서로 상속관계에 있는 객체 사이에서만 사용이 가능하다.

6. assignment(할당, 대입)연산자 (=)
= , += , -= , *= , /= , %= , &= , |= , ^= , >>= , <<= , >>>=
:기본적으로 피연산자간의 계산이 모두 끝난 값들을 변수에 저장하고자 할 때 '=' 연산자를 사용하여 값을 저장한다.
앞에서 봐온 클래스 파일들을 살펴보면 앞의 접두사로 자료형이 나타나고 뒤에 stroe가 붙은 opcode로 변환이 된다.

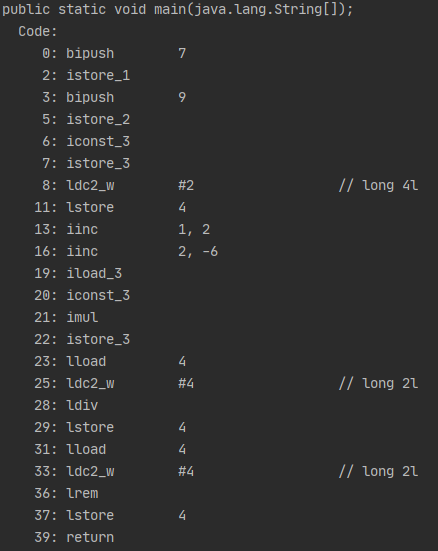
+= -= *= /= %= , &= , |= , ^= , >>= , <<= , >>>=
바이트코드를 분석하면 앞의 피연산자에 뒤의 피연산자를 연산한 값을 앞의 피연산자가 저장되어있던 local variable에 저장한다. 라는 의미로 해석을 하면 된다.
그러나 바이트코드를 분석하면 +=과 -=은 변수에 저장되지 않은 리터럴을 연산할 때 조금 다른 형식을 보인다.
+= 연산자는 피연산자에 해당하는 값이 변수에 저장되지 않은 값일 때면, 바로 해당 local variable의 위치를 찾아가 값을 더해버린다.
-= 연산자는 마이너스 연산을 하지 않고 해당 값의 부호를 반대로 바꿔버리고 +연산을 진행한다.
7. 화살표 연산자
->
:람다 표현식이라고도 불린다.
이름이 사실상 필요없는 한번만 생성하고 말 인스턴스를 생성하고 그 내부의 메소드에 매개변수를 주입하는 anonymous inner class 형태의 가독성이 떨어지는 형태의 코드를 개선하기 위해 생성된 연산자(?)이다.
(매개변수) -> {실행문} 의 형태를 사용한다. 매개변수의 이름은 마음대로 지을 수 있다.
예제는 아래와 같다.




개인적으로 추측했을 때 컴파일하면 같은 내용이 될 것이라고 생각했는데 내부의 코드가 달랐다.
새로운 Object를 생성하고 스택 맨위에 있는 값을 복사하는 연산이 한번 줄어들었다! 그리고
invokespecial이 사라지고 invokedynamic opcode가 생성되었다. invokespecial은 인스턴스 메소드를 호출하고 스택에 올리는것이다. 그리고 invokedynamic은 다이나믹 메소드를 수행하고 결과를 스택에 올리는 것이라고 한다. 그 둘의 차이점은 무엇일까?
invokedynamic ??? invokespecial ??? 무슨 차이인걸까?
javap의 옵션 -v를 사용해서 추가적인 정보를 확인해보자


람다식으로 코드를 변환했을 때에 못보던 코드가 생성된 것을 볼 수 있다.
바로 BootstrapMethods이다.
이것에 대해 설명하자면 이미 연산자와는 거리가 너무 멀어진 내용지만 더욱더 거리가 멀어져버리니 나중에 한번 더 알아보기로 하고 중요한 내용만 요약을 하자면 람다식을 사용하면 컴파일타임의 메소드 호출을 런타임으로 미뤄버린다. 따라서 첫 번째 람다 실행 이전에 내부클래스와 관련된 추가 공간에 대해 지불하지 않을 수 있다. 그리고 계산이 바이트코드에서 부트스트랩으로 이동하기 때문에 바이트코드가 작아지고 그에 따라 더 빠른 시작 속도를 얻을 수 있다. 그리고 바이트코드로부터 부트스트랩 메소드가 분리되었기 때문에 추후에 성능 개선을 이루어 하위 호환성을 맞추는데에도 도움을 준다.
다음과 같은 다양한 이점이 있는데 나중에 다룰 일이 있으면 한번 더 다뤄보도록 하자.
8. 3항 연산자
a ? b : c 의 형태를 지니는 피연산자가 3개인 연산자이다.
a가 참이면 b이고 a가 거짓이면 c라는 내용이다.
바이트코드를 해석하면 특별한 내용은 없다.


9. 연산자 우선순위
연산자의 우선순위는 매우 중요하다. 연산자의 우선순위에 따라서 바이트 코드에서 후위 표기식으로 변환되어 코드가 나타나기 때문이다. 다음 표는 위에 있을 수록 우선 처리되는 연산이다.

'Java > STUDY HALLE' 카테고리의 다른 글
| [Java] GitHub Library 사용법 (0) | 2020.12.06 |
|---|---|
| [Java] JUnit5 (0) | 2020.12.05 |
| [Java] 제어문 (0) | 2020.12.05 |
| [Java] 데이터타입, 변수, 배열 (0) | 2020.11.21 |
| [Java]JVM 기술 스택의 구조 이해하기 (0) | 2020.11.14 |